PRISM-break: Hoe werkt het eigenlijk? (deel 2)
De andere theorie over de werking van spionageprogramma PRISM die logisch klinkt: aftappen van glasvezelkabels dichtbij grote internetbedrijven.
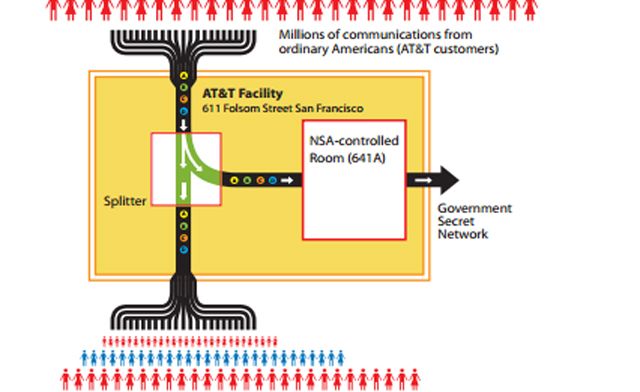
Naast de theorieën van Ashkon Soltani heeft onderzoeker Steve Gibson een eigen theorie ontwikkeld, gebaseerd op informatie die aan het licht kwam in 2006. Die komt voort uit de uitspraken die oud medewerker van het Amerikaanse telecombedrijf AT&T Mark Klein deed in een rechtszaak over het massaal afluisteren van internet- en telefonieverkeer. Zijn verhaal wordt ondersteund door verschillende gerechterlijke documenten, die samengevat zijn in dit document.
Gibson's theorie is dat de NSA data aftapt voordat het bij de in de PRISM-slides genoemde internetbedrijven aan komt. Dat aftappen gebeurt middels een splitter die het internetverkeer dat door de glasvezelkabels loopt splitst. Die splitter functioneert zoals een prisma (vandaar de naam PRISM). De ene helft van de data gaat door naar het bedrijf, de andere helft gaat rechtstreeks naar servers van de NSA. De splitters zijn geïnstalleerd in gebouwen waar de routers staan die het internetverkeer de wereld rondsturen. Ze zijn zo dicht mogelijk bij de verschillende bedrijven geïnstalleerd, om er voor te zorgen dat een zo groot mogelijk deel van de onderschepte data ook daadwerkelijk voor bedrijven als Google en Apple bestemd is.
Dat verklaart volgens Gibson ook meteen het verschil tussen de uitspraken van de technologiebedrijven ("de NSA heeft geen directe toegang tot onze servers") en de informatie uit de PRISM-slides van Edward Snowden ('collection directly from the servers of these U.S. service providers'). Omdat het aftappen gebeurt voordat de informatie bij de bedrijven aan komt, hoeven ze daar helemaal geen weet van te hebben. Dat zou betekenen dat de bedrijven niet gelogen hebben toen ze zeiden dat ze niet van het PRISM-programma wisten, of dat hun reacties ingefluisterd waren door veiligheidsdiensten.
Volgens Gibson lijkt ook de tijdlijn in de PRISM-slides overeen te komen met deze theorie. Het installeren van de aftappunten is een hoop werk en moet bovendien in het geheim gebeuren. Dat zou kunnen verklaren waarom Microsoft in 2007 al aan het programma is toegevoegd, Google in 2009 en Apple pas in 2012. Vanuit logistiek oogpunt bezien zou dat op die manier te verklaren zijn.

Om te snappen hoe het aftapsysteem in deze theorie werkt is enige basiskennis van de werking van het internet vereist. Daarom volgt hier een beknopte uitleg. Het internet is een verzameling van aan elkaar gelinkte netwerken. Die netwerken zijn in bezit van overheden, maar ook van bedrijven. Routers zorgen ervoor dat die netwerken met elkaar kunnen communiceren, het zijn eigenlijk doorgeefluiken van informatie.
Stel je tikt een zoekopdracht in op de site van Google. Die zoekopdracht reist via een router van je huis naar je eigen Internet Service Provider (UPC, Ziggo, KPN, enz) en vervolgens door naar andere routers die in gebouwen overal ter wereld staan. Dat zijn overigens niet de routers zoals we die thuis kennen, maar zogenoemde Big Iron Routers die enorme hoeveelheden data verwerken. Deze routers vormen samen eigenlijk de ruggegraat of het zenuwstelsel van het internet.
Informatie (zoals in dit voorbeeld je zoekopdracht) zal altijd de meest ideale route nemen om zo efficiënt mogelijk op de plaats van bestemming aan te komen. In dit geval is de bestemming de servers van Google. Jouw zoekopdracht is niet de enige informatie die richting Google gaat, overal op de wereld wordt Google gebruikt. Hoe dichter al die informatie bij de servers van Google komt, hoe geconcentreerder de aard van het verkeer zal zijn. Informatie die naar Facebook of Apple gaat heeft daar namelijk niets te zoeken, die servers staan op een andere plek.
Op die manier weten de veiligheidsdiensten zich ervan verzekerd dat ze informatie van de bedrijven gericht aftappen, mits de aftapping maar dicht genoeg in de buurt van de eindbestemming plaats vindt. Dat wordt waarschijnlijk dus ook bedoeld in de PRISM-slides waarin gezegd wordt dat de informatie rechtstreeks van de servers van die bedrijven af komt. Die informatie wordt ergens opgeslagen, daarover na de infographic meer.
NSA's datacenter in Utah

Alle informatie die afgetapt wordt wordt opgeslagen op de servers van de NSA. Om die informatie op te kunnen slaan heeft de veiligheidsdienst enorme datacentra met onvoorstelbare opslagcapaciteit, verspreid over heel Amerika. Momenteel bouwt de NSA in Utah een datacentrum met de gigantische capaciteit van 5 Zettabyte. Dat is 5 miljard Terabyte, ofwel 5000 miljoen Terabyte. Een Terabyte staat gelijk aan 1000 Gigabyte. Kosten van het datacenter: 2,1 miljard dollar. Hieronder vind je een infographic die laat zien hoe groot een zettabyte eigenlijk is.

Er is nog een aanwijzing dat PRISM werkt met het direct 'aftappen' vanaf belangrijke glasvezelkabels: de Britse geheime dienst GCHQ zou precies hetzelfde doen, maar dan bij een kwart van de onderzeese kabels die Groot-Brittannie binnenkomen. GCHQ zou de enorme hoeveelheid verzamelde informatie volgens Snowden drie dagen lang in een buffer opslaan en de metadata (de informatie over wie met wie communiceert) 30 dagen lang bewaren.